ChessGML: The Why and Wherefore
Andreas Saremba
The goal of this article is to make a plea for the development and adoption of an XML-based standard format that can facilitate the communication of any kind of chess data: games both commented and uncommented, problems, studies, computer program analysis etc. – simply anything relevant to the game of chess. It discusses the present state of data formats in the world of computers and chess, shows their problems and deficiencies and outlines the way to a better solution.
In order to illustrate the argumentation and to prove that we're not talking about nice but lifeless theories, the article discusses a prototypical implementation of the ideas presented here which I've chosen to call Chess Game Markup Language or ChessGML.
- Table of Contents
- 1. Brave new chess world
- 2. On closer inspection, however ...
- 3. The importance of being open
- 4. What's wrong with PGN?
- 5. Where do we want to go tomorrow?
- 6. XML makes the difference
- 7. A taste of ChessGML
- 7.1. The sample file
- 7.2. First observations
- 7.3. ChessGML, line by line
- 8. What's the goal
Chapter 1. Brave new chess world
Computers and the Internet have revolutionized the way how chess games are communicated to the public. Even the average player without any special knowledge or equipment can obtain the score of a grandmaster game immediately after it is finished and easily store it in his private database, where it joins some 100'000 others. This was unimaginable some years ago.
Besides the two reasons everyone knows and acknowledges, the triumph of the Internet and the enormous development of chess database programs, there was one factor that was equally important for this development: A common language for the encoding of chess games. It is Stephen J. Edward's merit that such a language exists; he not only perceived the need for a lingua franca of the chess world but defined and implemented it in a strict and concise way. In short time PGN (Portable Game Notation) has become indispensable, and no chess software can afford not to be able to read and write this format.
So why would anybody be foolish enough to propose something different?
Chapter 2. On closer inspection, however ...
The joy about the undeniable progress the chess world has made has blurred the view for some aspects of the situation that are a bit less obvious. Let us look at a few examples:
While you can get an ocean of uncommented games on the Internet, there is a remarkable lack of commented ones. I this due to mystery mongery, is it indolence or are there other reasons?
If you find games illustrated with diagrams and/or comments published on the Internet, they are mostly published in HTML format. This seems reasonable because it's the primary format of this medium. But given the facts that you can only use low-quality raster images for the diagrams, and that there are high quality, freely available vector fonts for chess pieces – why does nobody publish games in a widely used printable format like, for example, Adobe's PDF format?
There is a remarkable lack of quality and consistency in the published PGN files. For example, more often than not you will find several spellings of a player's name in one file, making it impossible to perform simple automatic processing like building a tournament table or gathering of statistical data.
It is my conviction that the primary reason for these and other insufficiencies is the lack of an interchange format for chess that is not only open but also powerful. Both of these two aspects are most important, so I will discuss them in some depth.
Chapter 3. The importance of being open
Users tend to think about software in terms of functionality and usability; they use to under-estimate the importance of data formats. How should they know better – it is the very purpose of good software to provide a wealth of functions while hiding the (necessary) complexity of the underlying data from the innocent user. After all, nobody cares for the bits and bytes that are scribbled on the disk.
In fact, everybody should care. Not for the details of the bits and bytes, of course, but for their data. They are, after all, for what all the effort is made. You may not have noticed so far that data in a proprietary (i.e. vendor-specific) format is less valuable than data in an open and standardized format. But you will notice this once you try to switch to a different software, only to learn that you have to say Goodbye to most of your data because they cannot be read by the new program. A comparable, although less dramatic situation will occur when you try to send your data to somebody else who does not happen to use the same software as you do.
The usual justification offered by software vendors says they have to use their own format because it's highly optimized for the particular needs of their program and that it saves both processing time and (main memory as well as disk) space. This would be more convincing if they wouldn't, at the same time, try to keep their formats secret by not documenting them or by even encrypting the data.
So what can you do if you try to protect your data for long-term use and/or want to offer them to as large an audience as possible? Three common approaches are known.
Use the market leader's software and blame everybody who does not.
This approach seems to be pragmatic, but it suffers from some major drawbacks:
You unnecessarily limit you choice of software products by making a decision based on one single criterion. And you will do this not only for the time being but for all future – the market leader is very unlikely to let you escape from your self-constructed prison. He will, in the contrary, feel encouraged to force you to pay for upgrades in regular intervals; you will have to be obedient because you fear to lose the ability to exchange data with others who have chosen the same approach.
You actively help to destroy the market – your approach will kill competition and consequently do harm to your own interests in the long run.
You will not get as much benefit as you thought – neither do you know whether the market leader will still exist 20 years from now, nor will you ever be able to force all people for whom you have to offer data to use the same software.
Use another vendor's software that is able to read and write the market leader's data format.
This is the scroogy approach, but choosing it has some consequences:
Any application best understands its own native format for which it has been designed; reading and writing another application's format (which is usually based on different ideas and goals) is a difficult and complicated undertaking, and experience shows that practical problems abound. (Did you ever try to open a complex Winword document in WordPerfect, StarOffice of FrameMaker? Then you know what I mean.)
Data formats are changed – sometimes even improved – as software develops; the market leader has the freedom to do what he wants, and the others have to catch up. You are in a very unfortunate position if your new software barely understands the data format of Megahard's Office 1999, but two months later the earthshaking 2001 version hits the street.
Use an open format.
An open format is one that is not only completely published but has been defined by an independent organization or group of people – possibly influenced, ideally supported, but definitely not dominated by the market leader(s). This approach is the only one that can be successful in the long run because it preserves your freedom and independence. But despite its great potential there are requirements to be met and dangers to be avoided:
An open format must be powerful and expressive. This means that it not only has to be able to describe the relevant aspects of its application domain; it also has to be based on a sound foundation that allows for extensibility and scalability.
An open format, despite its power, has to be comparetively simple in terms of processing. If it requires excessive effort for implementation, nobody will, despite all its virtues, invest the necessary amount of time and money to adopt it.
As a corollary, we can deduce that it helps if an open format is not an island but is based on a larger conceptual framework, supported by mature and stable tools. This will help in decreasing the overall cost of implementing the software and will give developers the chance to concentrate on that part of the software which deals with the semantics of the application domain.
An open format does not have to be a (potential) internal storage format for an application or a database format; in fact, any optimizations in terms of efficiency in time and space use to be in contradiction with the design goals stated above. As a consequence, applications are free to use internal data formats as they always did, provided they are also fluent in the open format used for data interchange.
Despite all the technical reasons that favour an open data format as opposed to closed, secret, vendor-specific ones, there is one very practical consideration that might speak against it: The market leaders often feel tempted to ignore an open format because they think it's a threat for their dominance. This applies in particular when the largest supplier of software is also the largest publisher of data, as is the case in the world of chess.
This danger will only be overcome if customers put real pressure on suppliers to support an open format, and if the market leaders get the impression that the overall increase in market size caused by more openness will more than outweigh the potential threats by the competition.
After these general considerations, let us return to chess, where we have an open, vendor-independent standard that is generally accepted, even by the market leader. But maybe the reason for this acceptance is that PGN is not powerful enough to be considered a serious threat?
Chapter 4. What's wrong with PGN?
It may be a bit surprising that I'm going to assert that PGN has major deficiencies although I stated earlier that it has been the decisive factor for the fast spreading of chess games on the Internet. This only appears to be a contradiction:
Everyone would agree that PGN is a simple format. Is it really? PGN is easy to read for humans, but for computer software it's only syntactically simple. For processing the moves of a game (written in SAN, Standard Algebraic Notation), a program needs to know about the semantics, i.e. the rules of the game. This is usually taken for granted, but the consequence is that it excludes most standard software from processing PGN. (Don't believe me? Give Winword a PGN file and tell it to produce long algebraic notation with figurines, with a diagram added after every 5th move. Hey, this would be a nice challenge for a VBA hacker contest!)
In general, no piece of software that was not specifically designed for the processing of PGN and chess moves can do anything reasonable with a PGN file.
If you have wondered what was meant by the term conceptual framework you will now see that the lack of such a framework for PGN constitutes a major deficiency. For example, the PGN standard is talking about things like handling of the newline character (section 3.2.2), lexicographical issues (section 4), tokenizing (section 7) etc. All these topics have nothing to do with chess, and therefore they should be handled where they belong: by specialized, basic standards that do nothing else but dealing with these topics.
Talking about these things in the definition of a chess-specific format is not only a cosmetic mistake; it implies that you cannot base your chess-specific software on a general library that implements these basic standards, but you have to hand-craft everything on your own. This is not only an inconvenience for programmers of chess software but – more importantly – prevents more demanding features from being implemented.
Just in case you don't believe me, let's take an example: the deplorable situation of incorrectly spelled names in PGN. There is no German grandmaster called Robert Huebner; his last name is Hübner. Interestingly, this correct spelling would even be possible with PGN. The German umlaut ü ist character 228 in the ISO-Latin1 character set, and the standard states (in section 4.1)
«PGN data is represented using a subset of the eight bit ISO 8859/1 (Latin 1) character set. ... the 64 code values from 192 to 255 are mostly alphabetic printing characters with various diacritical marks; their use is encouraged for those languages that require such characters.»
But because PGN does not have a foundation consisting of appropriate base standards, there is no generally available, cross-platform software support for the handling of these characters in PGN. In consequence, the whole chess world is effectively limited to what the English-speaking subset of mankind considers to be characters – which is a very narrow view from the perspective of this subset's complement.
It's even worse with characters outside the ISO-Latin1 set. Rumours are that a few chessplayers on this planet still read and write cyrillic. For these people, PGN even falls short on its own design criteria which include the statement:
«The system must be international. Chess software users are found in many countries and the system should be free of difficulties caused by conventions local to a given region.» (Section 2.2)
PGN is not free of these difficulties but instead introduces them – not for the computer, but for the humans.
Talking about the lack of a sound foundation formed by standards that are more general and wider in their approach, another problem comes to mind: PGN's complete lack of any concept of structure or hierarchy. Yes, you can put several games into one PGN file that can be arbitrarily long – but what is that good for? There is no method whatsoever to build larger units like, say, all games of a tournament, a team event or a collection of a master's games. Neither is there any possibility to add text describing a tournament, a round, a game or something else.
As an example, look at the PGN files distributed by Mark Crowther in The Week in Chess: They contain masses of games of several tournaments (many of them in their entirety), but without any structure, with the descriptive text being relegated to an external (ASCII or HTML) file. Would you accept a printed chess periodical to separate the tectual content from the games in a comparable fashion? Such a labour of love deserves a better and more expressive data format.
To summarize the statements made above, let me state my central assertion:
PGN is deficient by design, because it is not embedded in a larger conceptual infrastructure; this applies to theory (related and supporting standards) as well as to practice (standard software tools that would deal with the syntactical details and leave only the semantic aspects to chess software).
The conclusion is that PGN is a dead end and cannot be used as a basis for a future, more powerful standard.
Chapter 5. Where do we want to go tomorrow?
While it is true that sometimes the old has to be destroyed to build something new, I don't want to leave the impression that my goal is to denounce PGN or to convey it was incompetently designed. This is not the case, and I explicitly express my respect for the work of PGN's creator Steven J. Edwards. The judgements in this article are made from the perspective of the year 2000 which is vastly different from that in the early 1990s. The importance of generally available standards and open data formats has become common sense among software professionals, and the Open Source movement has given the individual developer in the computer world much more power than s/he ever had before. We can build our work on that of our predecessors, and this gives us not only a right but also a commitment for setting ourselves higher goals and standards of excellence.
What exactly is it, then, that will enable us to build a better open format for chess? Surprisingly, it is an "old" ISO standard way back from 1986, based on work from the late 60s. It is called SGML, an acronym for Standard Generalized Markup Language. Its fundamental idea is to define not a data format that would fit every need but a meta-language that allows to precisely describe special-purpose languages, one for every class of documents you need. Such a description (a DTD or Document Type Definition) is limited to defining the syntax of a document class, not the semantics; but it has the big advantage that it can be checked by software whether a given document really belongs to its claimed document class (in which case it is called valid) or not.
SGML was known for some years when PGN was developed, and one might ask why it wasn't used at that time. This would have been possible but impractical. In its first ten years of life as an ISO standard, SGML was used only by a relatively small group of companies and academic experts. This was caused by several reasons:
The language of the standard document (ISO 8879:1986) was difficult and intimidating, and there wasn't much tutorial material publicly available. It was a typical guru discipline, and to become a High Priest of SGML required considerable effort.
The standard was so general that it was extremely difficult to implement in its entirety; it took some years until James Clark created a nearly complete (and freely available) implementation of an SGML toolkit, but even with this excellent basis it was not easy to build real-world tools.
These factors made using SGML an expensive effort, and nobody tackled this task light-heartedly and without very convincing reason. (Not to speak of a very well-filled purse. The US DoD was among the adopters; got the idea?)
Given these facts, it is not surprising that PGN chose a more modest and realistic approach. (It would be interesting to learn whether SGML was considered and then rejected – I don't know that.) In any case, it is pretty clear that ten or even six years ago a chess standard based on SGML would have been ignored by most people.
So, what is different today?
Chapter 6. XML makes the difference
The World Wide Web has changed communication between humans so radically that one little aspect it also changed goes nearly undetected: The public perception of document format standards in general and SGML in particular.
It was a big luck that Tim Berners-Lee designed the Web around a document format that was modelled after the principles of SGML. Although he didn't develop a formal DTD for it – that was done later –, HTML essentially is an application of SGML. When people discovered that behind all these nicely formatted documents there was a very simple ASCII format they started writing their own HTML pages, and because there were no tools available in the early days of the Web, they had to do it with a simple text editor. As a consequence, they not only saw how HTML really looked but also got a convincing proof that you can do practical things with something based on SGML.
But there was still one problem, and it had to do with the fact that TBL's approach lacked the rigidity of the purists: The absence of a formal DTD for HTML encouraged browser vendors, in particular Netscape and Microsoft, to define and implement their own specific – and incompatible – enhancements. This was exactly the kind of situation that was intended to be avoided by a standard like HTML.
In 1996, a significant part of the SGML community figured it was the right time to unite the power of SGML and the popularity of HTML. They decided to define a more light-weight version of SGML by stripping many of the mundane, seldom-used features (and those that had become obsolete over time and were only of historic interest). This new standard, called XML (Extensible Markup Language) was published on February 10th, 1998, less than two years after the start of the project. It is not an ISO standard but a Technical Recommendation of the W3C, the World Wide Web Consortium.
Tim Bray, one of XML's chief designers, gives this consise and clear description of the goals: "XML is an attempt to package up the important virtues and most-used features of SGML in a compact, easily-implemented package that is optimized for delivery on the WWW. "
If you want to learn more about the birth of XML, see Jon Bosak's recollection.
XML may not have hit the streets yet, but behind the scenes a lot has happened. Several supporting standards have been or are being developed. One of the most important is XSL, the Extensible Style Language which defines how the information contained in an XML document can be styled, i.e. presented in print or online form.
It is not the purpose of this article to explain the technical details of XML or its co-standards. You will easily find more information on websites of the W3C, OASIS or XML.com, to name a few. Instead, we will continue our tour with a look at ChessGML.
Chapter 7. A taste of ChessGML
This chapter shows and discusses an extract of the ChessGML representation of one of the great tournaments in chess history.
7.1. The sample file
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE chess PUBLIC "-//A.Saremba//DTD chessgml//EN" "chess.dtd">
<!-- $Id: 1907-karlsbad.san.xml,v 1.2 2000/03/11 14:11:50 sar Exp -->
<chess>
<tournament>
<eventinfo>
<event>Großes Internationales Schachmeister-Turnier</event>
<site>Karlsbad</site></eventinfo>
<players>
...
<player id="Maroczy.Geza" table-ref="sw-2">
<person cbuffId="Maroczy,G">
<surname>Maróczy</surname><firstname>Geza</firstname>
</person>
</player>
...
</players>
<crosstable>
<ct-line rank="1" points="15">
<player-ref ref="Rubinstein.Akiba"/>
<self/>
<result res="draw" why="agreed" game-ref="game166" c="b" opp-id="Maroczy.Geza"/>
...
</ct-line>
<ct-line rank="2" points="14" halfpoint="1">
<player-ref ref="Maroczy.Geza"/>
<result res="draw" why="agreed" game-ref="game166" c="w" opp-id="Rubinstein.Akiba"/>
<self/>
...
</ct-line>
</crosstable>
...
<rounds>
<round nr="1">
<roundinfo><date day="20" month="08" year="1907"/>
</roundinfo>
<game id="game1">
<gameinfo>
<opponents>
<white><player-ref ref="Berger.Johann"/></white>
<black><player-ref ref="Spielmann.Rudolf"/></black></opponents>
<result res="draw" why="agreed"/>
</gameinfo>
<moves><sanMoves>
1. d4 d5 2. e3 Nf6 3. c4 e6 4. Nc3 c5 5. Nf3 Nc6 6. Bd3 dxc4 7. Bxc4 a6
8. a3 b5 9. Bd3 Bb7 10. O-O Qc7 11. Qe2 Bd6 12. dxc5 Bxc5 13. e4 Nd4
14. Nxd4 Bxd4 15. Bd2 Rd8 16. Rac1 Qb8 17. Nd1 O-O 18. Bc3 Qf4 19. Bd2
Qh4 20. Re1 Ng4 21. h3 Ne5 22. Bb1 f5 23. Kh1 f4 24. f3 g5 25. Be3 g4
26. Bxd4 Rxd4 27. Qf2 Qxf2 28. Nxf2 gxf3 29. Ba2 Rd2 30. Bxe6+ Kh8 31.
Kg1 fxg2 32. Red1 Rxb2 33. Bd5 Bxd5 34. Rxd5 Re8 35. Rxe5 Rxe5 36. Nd3
Rxe4 37. Nxb2 Re3 38. a4 f3 39. axb5 axb5 40. Rd1 Kg7 41. Nd3 Re2 42.
Nf4 Re4 43. Nd5 Re2 44. Nf4 Re4 45. Nd5 Re2 1/2-1/2
</sanMoves></moves>
</game>
<game id="game2">
...
</game>
...
</round>
<round nr="2">
...
</round>
...
</rounds>
</tournament>
</chess> |
7.2. First observations
7.2.1. Tags
If you have ever seen an HTML file in a text editor, this should look at least a bit familiar to you. Not only text, but lots of words in angle brackets; these are called tags, which together form the markup for the text. That's the meaning of the letter M in both HTML (HyperText Markup Language) and XML (Extensible Markup Language).
But you notice that the names of the tags are different: No <HTML>, <BODY> or <P>, but things like <chess>, <tournament> or <game> instead. This shows the fundamental difference between HTML and XML:
While HTML is limited to a fixed set of tags, you can invent your own tags in XML. With these tags, you can express what is the meaning of your text's content, not only how it shall be presented to the reader. This is the meaning of the letter X in XML.
You may remember that the term meta-language was used for XML's father SGML earlier, and it should be clear by now what was meant: SGML and XML do not define any fixed semantics or tag names, but give just a framework of rules that must be obeyed when defining an application specific markup language (like HTML or ChessGML). There are myriads of potential markup languages for every possible field of human interest.
7.2.2. Hierarchy
The next important fact is not quite as evident, and you even may not have noticed it in HTML files: Adding markup to a file by using tags not only gives you the possibility to describe the meaning of contents, but also lets you add a hierarchical structure to your data. This will become immediately obvious when we look at a graphical representation of the document you saw above
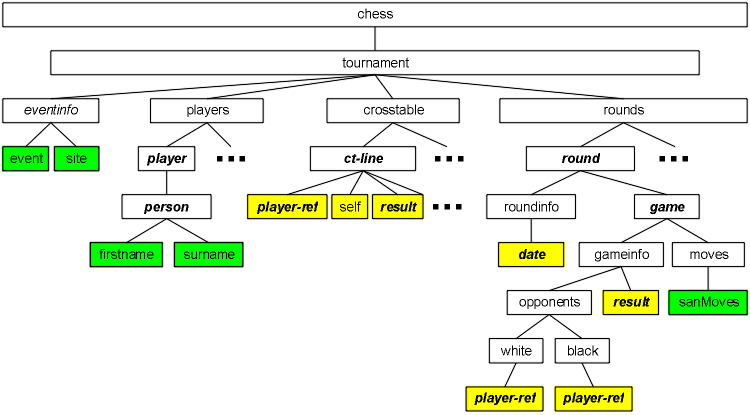
This is what mathematicians call a tree, consisting of nodes (depicted as rectangles) corresponding to the elements of the XML document and of edges representing a parent/child relationship. An element is a child or subelement of another (parent) element if it is directly nested inside the parent, as in the following example, where eventinfo is the parent of event and site:
<eventinfo> <event>Großes Internationales Schachmeister-Turnier</event> <site>Karlsbad</site></eventinfo> |
This is made possible by a simple syntactical construct: Instead of giving each element just one tag (as in PGN) it has two, a start tag (<eventinfo> for example) and an end tag (</eventinfo>). Everything inbetween is the content of the element, consisting of subelements or text. Mixed content, both subelements and text, is possible, but we don't see that in our example.
Note: This concept is not so extremely clever or subtle that its invention would have gone beyond the scope of the designers of the PGN standard. But keep in mind that defining such a concept is not enough – you also have to write software that is able to process such files. This is much harder in the case of a hierarchical structure, so you will introduce it only when you can be confident that you have the resources to implement it. Under the constraints of limited time and resources, the KISS principle (Keep It Simple and Stupid) is not the worst approach.
There are different graphical representations of the nodes in our tree, showing the different roles of the nodes:
Green nodes correspond to elements with text content.
Uncolored nodes correspond to container elements that have no text content, but subelements.
Yellow nodes correspond to elements that have neither text content nor subelements.
There is a second kind of difference:
An element name written in bold italic means that the element contains additional information in attribute(s) in its start tag; for example, <round nr="1"> doesn't start an arbitrary round but the first one.
An element name written in normal style depicts an element without any explicit attributes, for example <chess>. Note the cautious wording; there may be non-explicit attributes (which means: attributes with default values) hidden in the DTD, but that's a different topic.
7.3. ChessGML, line by line
We will now examine our example in more detail.
<?xml version="1.0" encoding="iso-8859-1"?> |
This is not an XML tag, but a processing instruction (identified by the starting sequence <? and the ending sequence ?>. It tells the parser that this is an XML file fitting the W3C's XML Technical Recommendation. Every XML document has to start with an XML declaration.
The optional encoding attribute tells the XML parser that characters outside the ASCII range (for example the ó in Maróczy's name) are encoded according to the ISO Latin1 standard, also called ISO-8859-1; if an XML file does not use one of the two standard encodings UTF-8 or UTF-16, it has to announce which one it uses.
We won't be able to discuss this topic here in depth. You will probably never have to deal with these issues if you are not a software developer because the XML software will handle it.
<!DOCTYPE chess PUBLIC "-//A.Saremba//DTD chessgml//EN" "chess.dtd"> |
This line is the doctype declaration; it says that this XML document must conform to the ChesssGML DTD (Document Type Definition). A validating parser can check whether this is true and, if not, emit the appropriate error messages; in this case, you would know that the processing software will not get the input it expects. Take it simply as a promise – the document promises that it conforms to certain rules.
<!-- $Id: 1907-karlsbad.san.xml,v 1.2 2000/03/11 14:11:50 sar Exp --> |
This is a comment, identified by the starting sequence <!-- and the ending -->. Think of it as an equivalent of comments in computer programs – something that does not belong to the content proper but gives additional information. In this case, it's a version information about the file, generated by CVS, the Concurrent Versions System. (XML files are text files, so you can put them into a versioning system very easily; it will know nothing about elements and attributes like an XML repository would do, of course.)
<chess> ... </chess> |
This is the start and the end tag of the document. It is little more than a wrapper around the document contents.
<tournament> ... </tournament> |
Now we start with the real content – this ChessGML file contains a tournament, not just an arbitrary collection of games, a single game, a study or something else.
<eventinfo> <event>Großes Internationales Schachmeister-Turnier</event> <site>Karlsbad</site></eventinfo> |
First comes some information about the tournament: Its name (copied from the official program, published in April 1907 and quoted here from the tournament book by Marco and Schlechter) and the site. Both are in German – in 1907, Karlsbad (now Karlovy Vary, Czech Republic) belonged to the Austrian monarchy.
This information should be in the ChessGML file, but I haven't yet found a satisfactory way to express these facts (names of cities and countries and sometimes even of players changing over time) in a precise and concise manner.
<players>
...
<player id="Maroczy.Geza" table-ref="sw-2">
<person cbuffId="Maroczy,G">
<surname>Maróczy</surname><firstname>Geza</firstname>
</person>
</player>
...
</players> |
Most of this should be obvious without much explanation, but a few comments seem to be appropriate:
The <player> element has an attribute id, which the DTD declares to be of type ID. This is a standard XML (and SGML) attribute type which guarantees that the id value has to uniquely identify the element. This makes the element referencable; you will notice that there are <player-ref> elements later in the file carrying a ref attribute. These are the references to the player elements. If you have ever seen one of the inconsistently tagged PGN files that are so common in the Internet chess archives, you will know what's the reason: You don't have to write the player's name several times but only once because all other occurences of the player only reference this one and only definition. This is one of the nice gifts when using a standard like XML: You don't have to invent your own methods to guarantee this kind of consistency, the methods are there, the tools support them – just make use of them.
There is one little downside: The rules of XML forbid to use some characters in ID values, a comma for example. So I had to transform the names into something that is allowed when translating the PGN file into ChessGML. But then, correcting the spelling of Maróczy's name (it was Maroczy in the PGN, as we would expect) was easy, because it had to be done in one place only.
There is another attribute in the player element, sw-ref, which has the sole purpose to make the generation of a progressive table easier.
The person element has an attribute named cbuffId which contains the original name from the PGN file. The name of the attribute makes a reference to Anjo Anjewierden's excellent CBUFF, which adresses (not only) the problem of inconsistent player names. His database contains the names, nationality, birthdate and ELO ratings for thousands of players, and every player has a unique identifier that can be safely used in PGN (and ChessGML) files. Mark Crowther does this in The Week in Chess; I hope that Anjo's method to identify players will become a standard accepted and used by everone who publishes chess data, and that he will continue to develop and even extend it. You should consider the attribute name cbuffId for the identification of the player as an appreciation of the importance of Anjo's work. He let me know in a private communication that he is working with XML in his professional life and has already implemented an XML export filter for his player database; so we can reasonably hope to hear more from hím in the future.
The player name that is really used for output is in the surname and firstname subelements of person. The contents of these elements has been hand-edited because it is not possible to find a general rule how to extract this information from a PGN file (in particular, when it's not there).
<crosstable> ... </crosstable> |
Obviously, this is the element that contains the tournament crosstable. Strictly speaking, the crosstable contains no information that cannot be deduced from the rest of the ChessGML file. But it makes it easier for SGML/XML tools to process the file, so the DTD allows it to be there (optionally), and the transformation from PGN to ChessGML has generated it.
<ct-line rank="1" points="15"> <player-ref ref="Rubinstein.Akiba"/> <self/> <result res="draw" why="agreed" game-ref="game166" c="b" opp-id="Maroczy.Geza"/> ... </ct-line> |
This is one line from the crosstable. It first contains the player (with a reference via an attribute of type IDREF pointing to the ID attribute of the player element); then come all the results, with the non-played game Rubinstein - Rubinstein represented by the (empty) self element. (This is a case when even an empty element without attributes can carry information!). All the information of the result element is in its attributes, which even contains two IDREF attributes, one pointing to the opponent and one to the game. You will have no difficulty finding the corresponding ID attributes in player and game.
It is not possible to deduce from this sample (or even from the complete ChessGML file) what are the possible values for an attribute like why; if you ever dare to look into the DTD you will see that there is a fixed set of possible values like mate, stalemate, resigned etc. Unfortunately, there is no way to express any relationship between attribute values; it would be syntactically possible, for example, to have a result like <result res="draw" why="resigned" ...>. This is a clear weakness of XML (and SGML), and a new standard (XML Schemas) is being developed that will be more powerful than Document Type Definitions.
<rounds> <round nr="1"> ... </round> ... </rounds> |
Now we come to the real content of the tournament; each round is represented by an element of the same name, with an attribute giving the round number. Note that it wouldn't be strictly necessary to give the rounds in numerically ascending order because there are numerous tools that have access to the complete document content without relying on any particular order of the elements; but it makes processing easier for tools that expect the elements to be in the right order.
<roundinfo><date day="20" month="08" year="1907"/> </roundinfo> |
The date element gives the date when the round was played instead of repeating this information for every game like in PGN. Day, month and year are given as named attribute values instead of relying on the correct interpretation of a date format like "1907.08.20", which makes processing easier.
<game id="game1"> ... </game> |
A game, at last, nicely identified by an ID attribute. (Any unique value for this attribute would be ok, but game<xx> makes things more comprehensible for a human reader.)
Perhaps you remember that we talked about attributes that are given default values in the DTD. If you run this file through an XSL identity transform, the start tag becomes <game id="game1" type="chess" variant="classic">. This might give you an impression of possible future enhancements, with classic being replaced by fischer-random or janus-chess (and maybe even chess by go?).
<gameinfo> <opponents> <white><player-ref ref="Berger.Johann"/></white> <black><player-ref ref="Spielmann.Rudolf"/></black></opponents> <result res="draw" why="agreed"/> </gameinfo> |
Again, we use the player-ref elements here with an IDREF attribute. We can do so because this game lives in the context of a tournament file; but what do you do if you want to extract this game to send it to somebody as a separate file or to incorporate it into a collection of games?
The answer is, of course, "it depends". If we had a standard for identifying players (like the CBUFF approach described above), it would be perfectly ok to use a person element with just a cbuffId; an alternative would be a person element with surname and firstname explicitly given. Both can be done automatically, and the ChessGML distribution contains a little program (extract-games.xsl) that extracts all games from a ChessGML tournament file into standalone game files.
Note that the result element has only two attributes here, as opposed to the result elements in the crosstable. This shows that attributes can be used very flexibly in a context dependent way.
<moves><sanMoves> 1. d4 d5 2. e3 Nf6 3. c4 e6 4. Nc3 c5 5. Nf3 Nc6 6. Bd3 dxc4 7. Bxc4 a6 ... Nf4 Re4 43. Nd5 Re2 44. Nf4 Re4 45. Nd5 Re2 1/2-1/2 </sanMoves></moves> |
You might ask why we use Standard Algebraic Notation here to represent the moves of the game. After all, I stated earlier that software has to understand the rules of chess in order to be able to process SAN, which is certainly not the case for standard XML software.
The answer is that the format you use depends on what you want to do with the ChessGML file and what tools you intend to use for processing the file. If you use a chess database that has a ChessGML import filter (and I hope all of them will have in the future), SAN is a perfectly usable format because it's easily understood by the software. If you intend to process your file with standard XML tools, however, the content of the sanMoves element will be just a sequence of characters without any semantics for the tool, so it's necessary to transform it into something meaningful. Fortunately, this is not too difficult; the ChessGML distribution contains a Java program (CgmlSan2Tag.java) that transform the moves from SAN format to an XML tagged format. Then we get the following:
<moves ply-count="90"> <mp><m c="w"><p c="w" n="p"/><sq n="d2"/><sq n="d4"/></m> <m c="b"><p c="b" n="p"/><sq n="d7"/><sq n="d5"/></m> </mp> <mp><m c="w"><p c="w" n="p"/><sq n="e2"/><sq n="e3"/></m> <m c="b"><p c="b" n="n"/><sq n="g8"/><sq n="f6"/></m> </mp> ... <mp><m c="w"><p c="w" n="n"/><sq n="f4"/><sq n="d5"/></m> <m c="b"><p c="b" n="r"/><sq n="e4"/><sq n="e2"/></m> </mp> </moves> |
Ugly and a waste of space, isn't it? Yes, but this is pure XML, and therefore it can be easily processed by XML tools. And there's no need to permanently store the transformed file which has 5 to 6 times the size of the ChessGML file in SAN format. You can generate it on-the-fly when needed; the smaller file already contains all the necessary information.
Please note that this is a most important point: XML does not force you to tag the complete contents of a document in XML syntax; there may be parts that are just sequences of characters for an XML tool but have meaning to tools that know about the application domain's syntax and semantics. There may even exist different representations of the same content in parallel, each one of them best suited for a particular use.
This ends our little tour, and I think you have got an impression of what can be done with XML. We have only scratched the surface; the next thing we might do could be adding comments to games and textual descriptions to the tournament as a whole. But let us do one step after the other.
Chapter 8. What's the goal
It is not too difficult to define a DTD for chess (as for most application domains). It is much more difficult to define a good one that is accepted and used by most people. But this must the primary goal, because a fragmentation of the chess world into separated user communities using different data formats for the same purpose would be a disaster. We need one open, powerful and expressive format for exchanging chess information. With the ChessGML distribution available at my website I have provided a prototypical implementation of the ideas presented in this article, which I suggest to be a starting point for a discussion.
But defining a sound technical base is only the first step: The ultimate goal is not a technical one. Chess is in a unique position among games and sport contests in that we have an enormous wealth of beautiful and instructive material (games with and without comments, studies, problems etc) to enjoy. Many of them are not or no longer under copyright, so they could be freely accessible for everyone. The market for chess books in some languages is not very large, but an equivalent of the successful Project Gutenberg would make it possible to make the works of the great masters of the past available to most chessplayers in the world. Remember that we have an advantage: Chess books are easier to translate than literary works!
There is one important aspect we must not forget; it cannot be the purpose of an open exchange format to help anybody in stealing other peoples' intellectual property. We have to respect copyright. Yet, there is still enough interesting material – historical as well as new one, contributed by volunteers, tournament sponsors and others. And copyright ends 70 years after the author's death, which already gives us the writings of Steinitz, Schlechter and Marco. Karlsbad 1907, one of the great tournament books of chess history, would make a fine candidate for the first ChessGML-ified book. And Tarrasch died in 1934; why not celebrate him with an Internet edition of “300 Schachpartien” or "Petersburg 1914" in 2004, translated to a dozen languages?
The contents is there, the technical infrastructure (the Internet) is there, we have the necessary tools do define an appropriate data format – what are we waiting for? Let's share the treasures of today and of our heritage. It's time to start an equivalent of Project Gutenberg for chess.